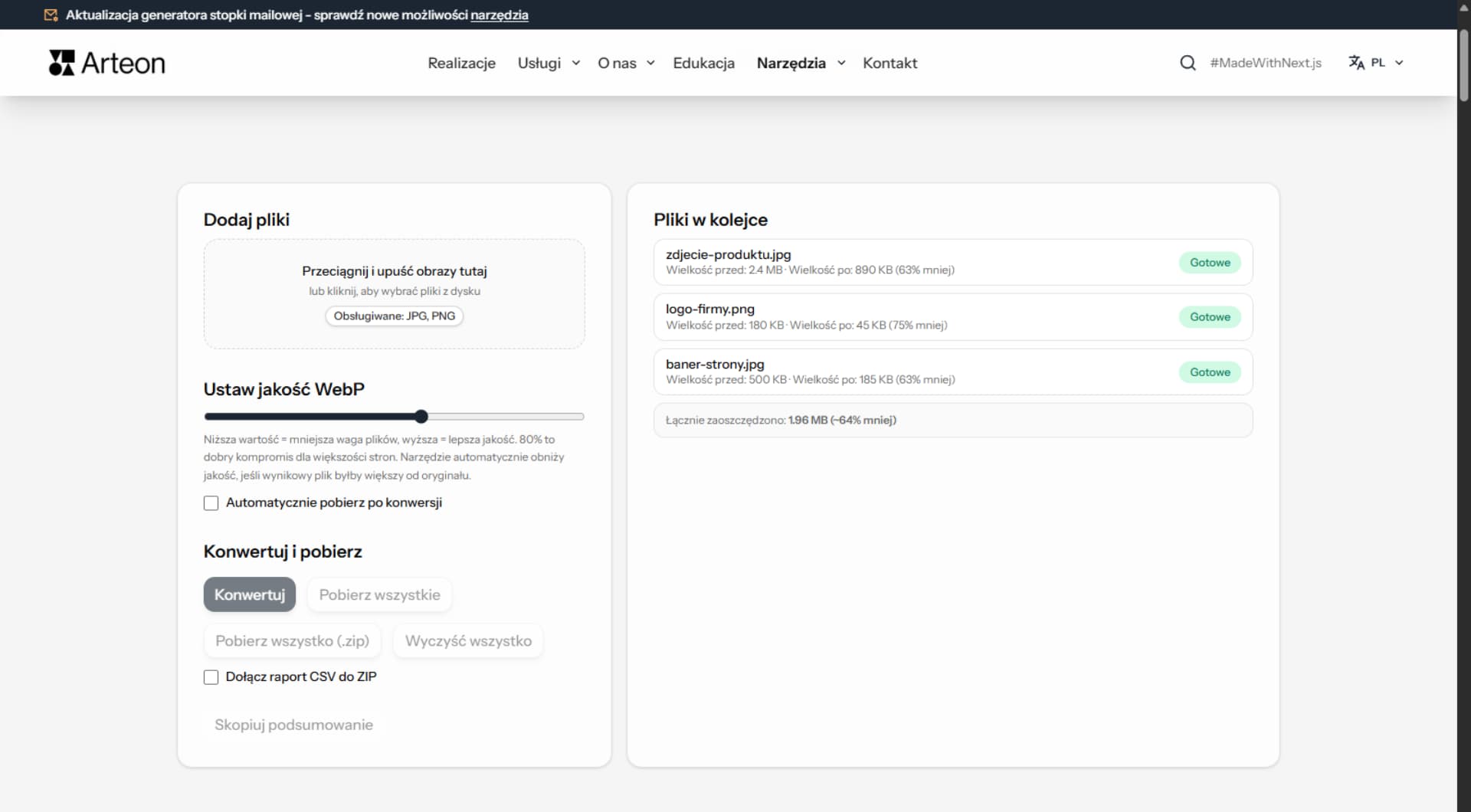
1. Wklej kod HTML
Wklej kod HTML w pole tekstowe lub wgraj plik z dysku.
Przenosisz treści z WordPressa do Notion lub Git? Konwerter usuwa tagi HTML, dając Markdown gotowy do README.md – bez rejestracji.
HTML to język znaczników stron internetowych — potężny, ale trudny do czytania i edycji bez specjalistycznych narzędzi. Markdown to prosty format tekstowy, w którym # Nagłówek zastępuje <h1>Nagłówek</h1>, a **pogrubienie** zastępuje <strong>pogrubienie</strong>. Jest standardem w dokumentacji GitHub, GitLab, Bitbucket, Notion, Obsidian i generatorach stron statycznych (Hugo, Jekyll, Gatsby, Astro).
Konwersja HTML na Markdown jest niezbędna przy migracji treści ze starego CMS-a (WordPress, Joomla) na generatory statyczne, przenoszeniu artykułów do repozytorium Git, tworzeniu dokumentacji technicznej i archiwizowaniu treści ze stron internetowych w czytelnym formacie tekstowym.
Konwerter rozpoznaje tagi semantyczne HTML: nagłówki (h1–h6), listy (ul, ol), linki (a), obrazy (img), bloki kodu (pre, code), tabelki (table) i formatowanie tekstu (strong, em, del). Pomija tagi nierelewantne dla Markdown (div, span, script, style).
Cała konwersja odbywa się lokalnie w przeglądarce — dane nie są wysyłane na serwer. Bez rejestracji, bez limitów, bez śledzenia.
| Funkcja | HTML | Markdown |
|---|---|---|
| Dane zagnieżdżone | ✓ | — |
| Dane tabelaryczne | ✓ | ✓ |
| Walidacja schematu | ✓ | — |
| Czytelność dla człowieka | — | ✓ |
| Standard API | — | — |
| Zwięzła składnia | — | ✓ |
Konwersja HTML na Markdown polega na zamianie tagów HTML na odpowiednie znaczniki tekstowe. Na przykład tag <h1> staje się linią zaczynającą się od #, tag <strong> zamienia się na tekst otoczony podwójnymi gwiazdkami, a lista <ul> na linie z myślnikami.
Konwerter rozpoznaje tagi semantyczne HTML i inteligentnie mapuje je na składnię Markdown. Elementy HTML, które nie mają odpowiednika w Markdown (np. <div>, <span>), są pomijane, a ich zawartość tekstowa jest zachowywana.
Style CSS i atrybuty HTML są usuwane, ponieważ Markdown nie obsługuje formatowania wizualnego. Wynikowy tekst jest czysty, czytelny i gotowy do użycia w dokumentacji, repozytoriach lub blogach statycznych.
Kilka wskazówek, które pomogą uniknąć problemów:
Konwerter obsługuje najważniejsze tagi semantyczne: nagłówki (h1–h6), paragrafy, listy (ul, ol), linki, obrazy, bloki kodu, tabele, cytaty i wyróżnienia tekstu (bold, italic).
Nie. Cała konwersja odbywa się lokalnie w przeglądarce. Kod nie opuszcza komputera.
Elementy bez odpowiednika w Markdown (np. div, span) są pomijane - zachowywana jest tylko treść tekstowa.
Markdown jest standardem w repozytoriach GitHub/GitLab, dokumentacji technicznej, blogach statycznych (Jekyll, Hugo), notatnikach Jupyter i systemach CMS obsługujących Markdown.
Tak. Cała konwersja odbywa się lokalnie w przeglądarce — kod HTML nie jest wysyłany na żaden serwer. Po zamknięciu strony dane są automatycznie usuwane z pamięci.
Konwersja zachowuje treść i strukturę semantyczną (nagłówki, listy, linki, obrazy), ale informacje o stylowaniu CSS są usuwane, ponieważ Markdown nie obsługuje formatowania wizualnego.
Wynikowy Markdown możesz użyć w repozytoriach GitHub i GitLab (pliki README.md), dokumentacji technicznej, blogach statycznych (Jekyll, Hugo, Gatsby), notatnikach Jupyter i systemach CMS obsługujących Markdown.
Tak. Modele językowe takie jak GPT-4 i Claude lepiej przetwarzają Markdown niż HTML – tagi i atrybuty HTML dodają szum do kontekstu. Konwersja HTML na Markdown przed wysłaniem do API modelu językowego zmniejsza zużycie tokenów i poprawia jakość odpowiedzi.
Masz pomysł na nową funkcję, znalazłeś błąd lub chcesz zaproponować inne narzędzie? Napisz do nas – odpowiadamy w ciągu 24 godzin.

Zmień rozmiar, wykadruj i przekonwertuj zdjęcie. Gotowe formaty, okrągłe avatary, eksport JPG/PNG/WebP.

Sprawdź długość tytułu i opisu strony w pikselach. Podgląd wyniku w Google na żywo.
Zamień pliki PNG na JPG. Konwersja w przeglądarce, bez limitu plików i rejestracji.

Stwórz favicon.ico dla swojej strony z jednego obrazu. Bez logowania i rejestracji.

Wygeneruj 9 palet z jednego koloru: monochromatyczną, komplementarną, triadyczną i inne. Kody HEX.
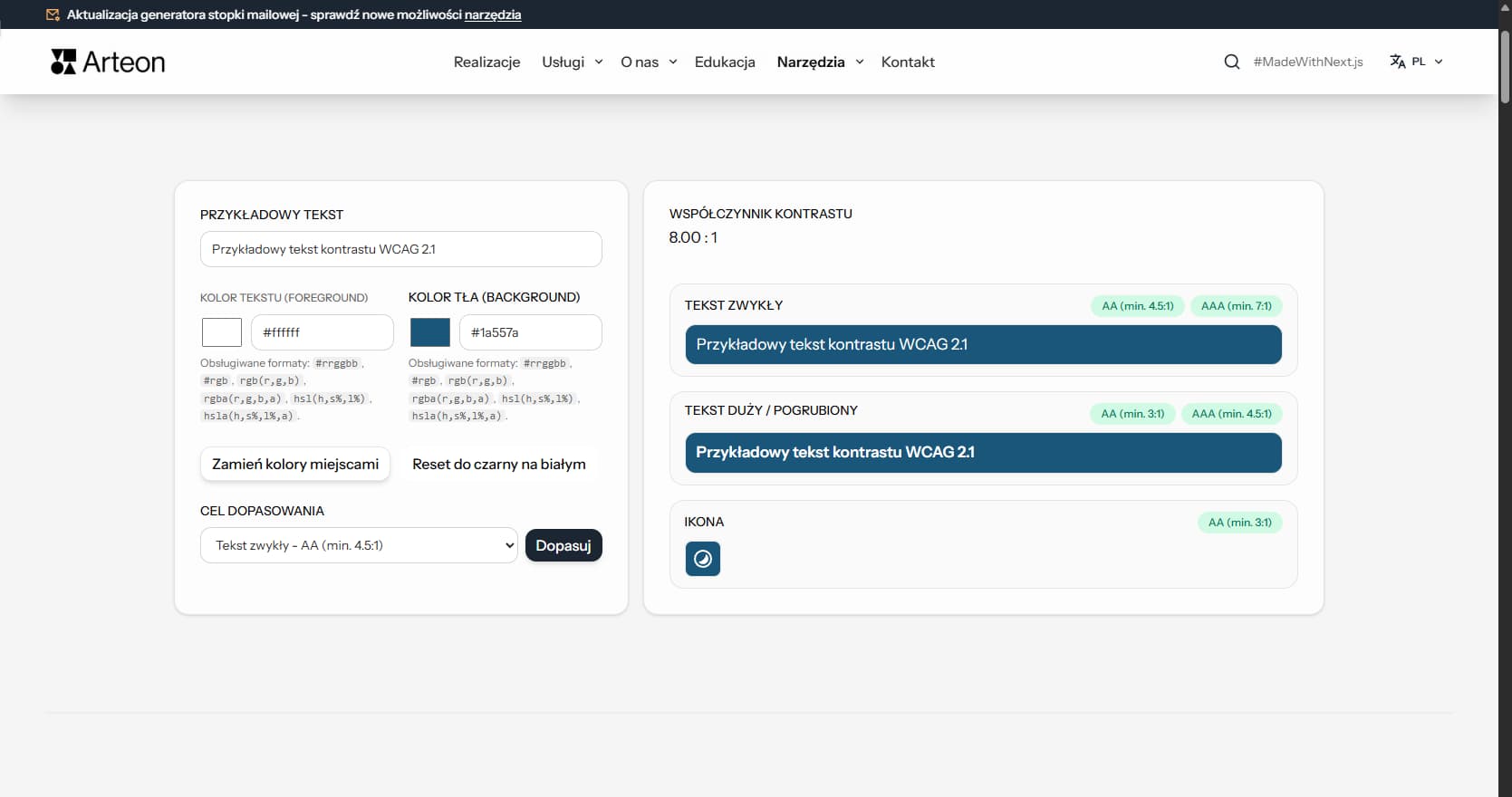
Sprawdź kontrast tekstu i tła według WCAG 2.1 AA i AAA. Automatyczna korekta kolorów.

Stwórz kod QR do strony, wizytówki vCard lub druku. Eksport PNG i SVG, bez rejestracji.

Policz słowa, znaki, zdania i czas czytania. Sprawdź czytelność tekstu wskaźnikiem Flesch-Kincaid.